Google Cloud Billing Export Setup
This guide shows how to use Google Cloud’s billing export service to export datasets that can be used in BigQuery.
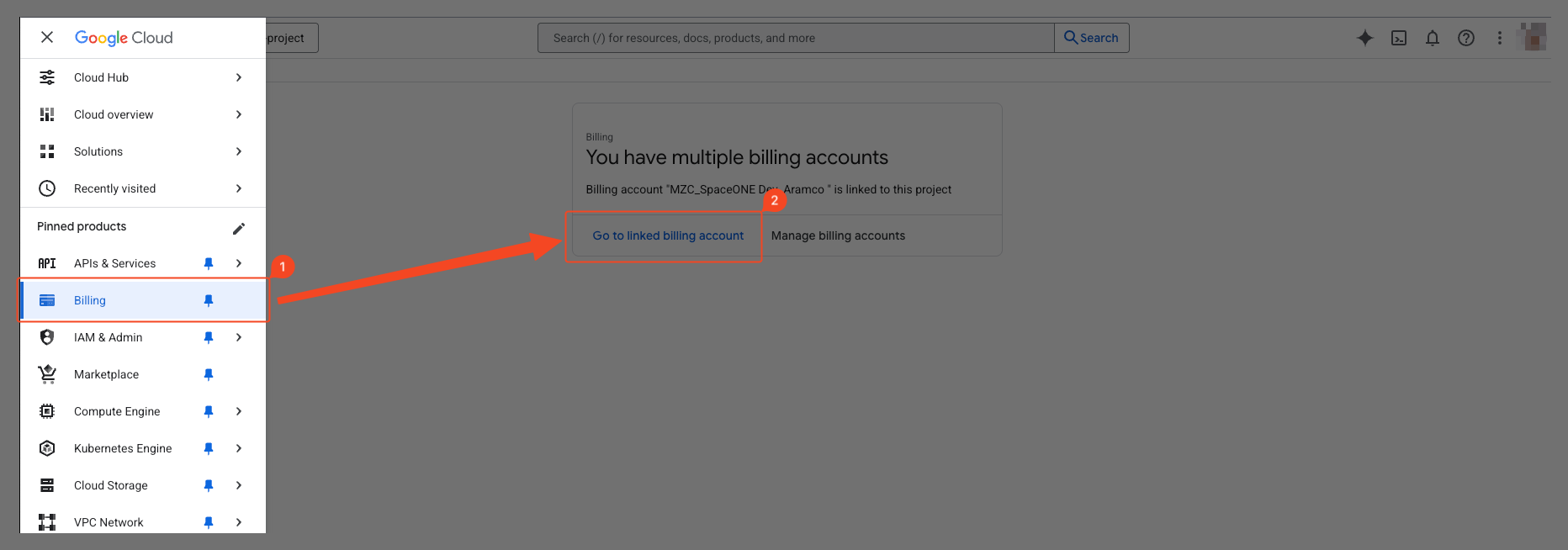
Select ‘Billing’ > ‘Go to Linked billing account’ from the navigation menu (☰) in the top left.
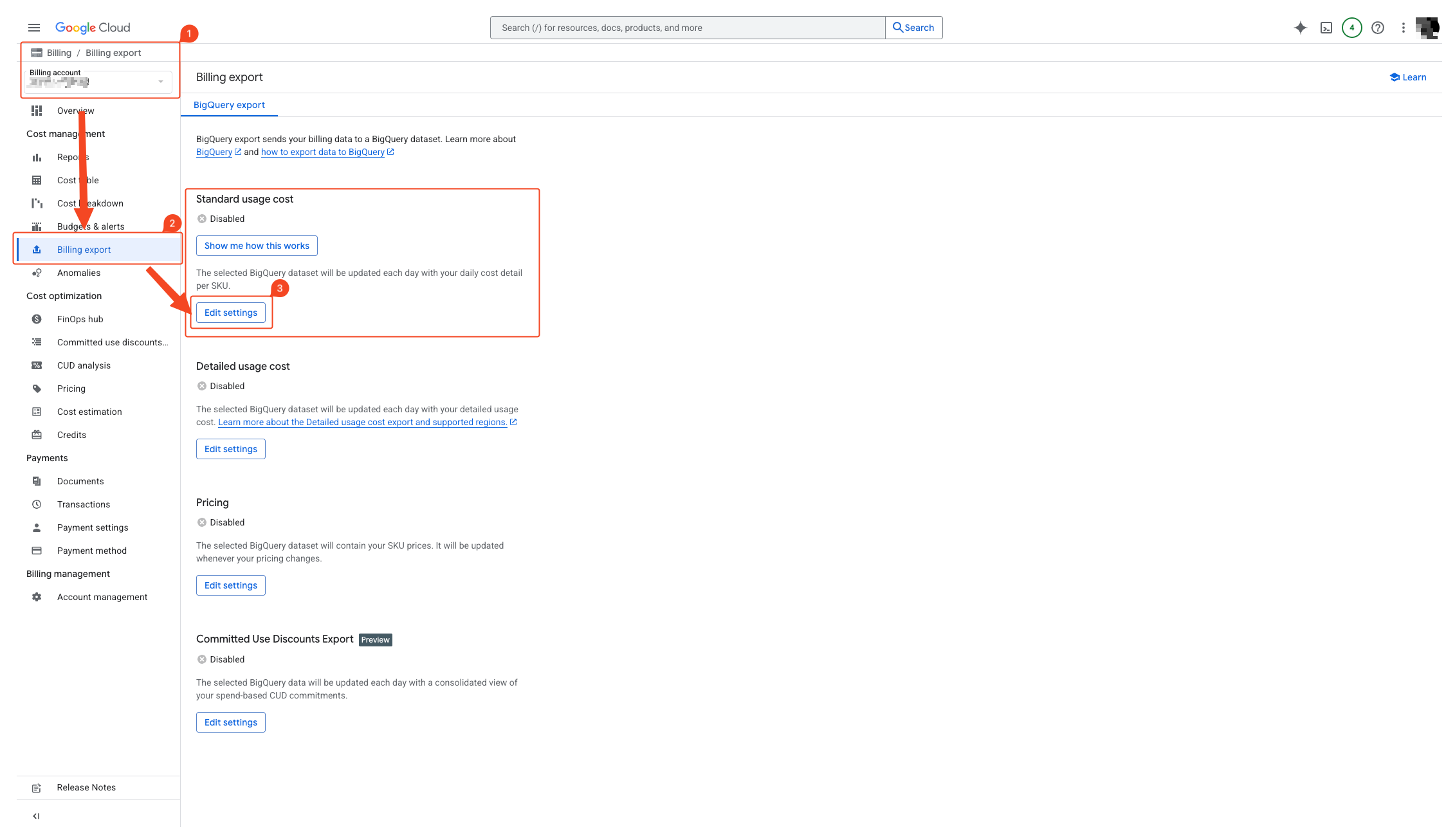
- Select the correct billing account from the left billing account dropdown.
- Select ‘Billing Export’.
- Select edit settings in Standard usage cost.
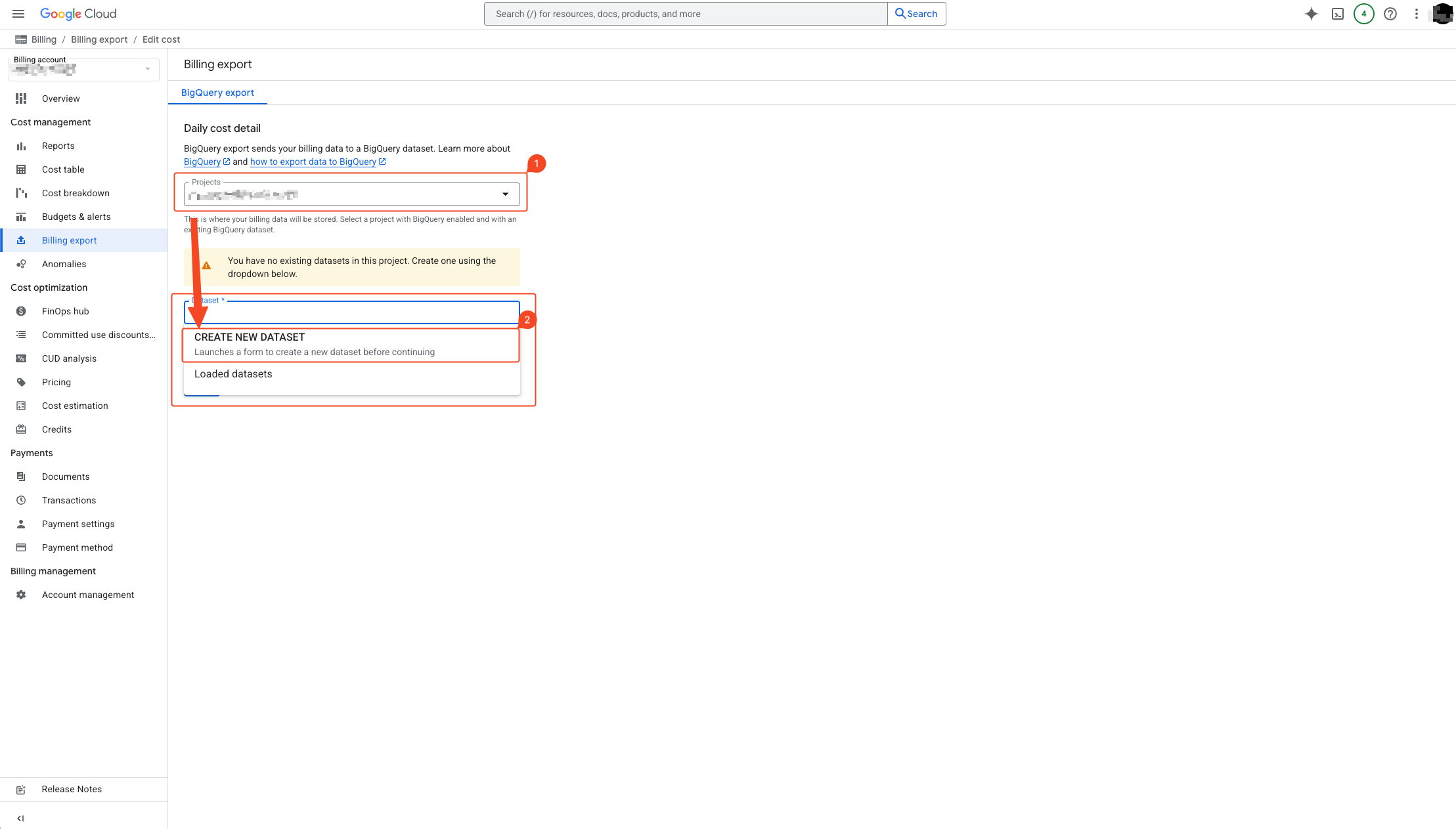
- Select the appropriate project.
- Select create new dataset.
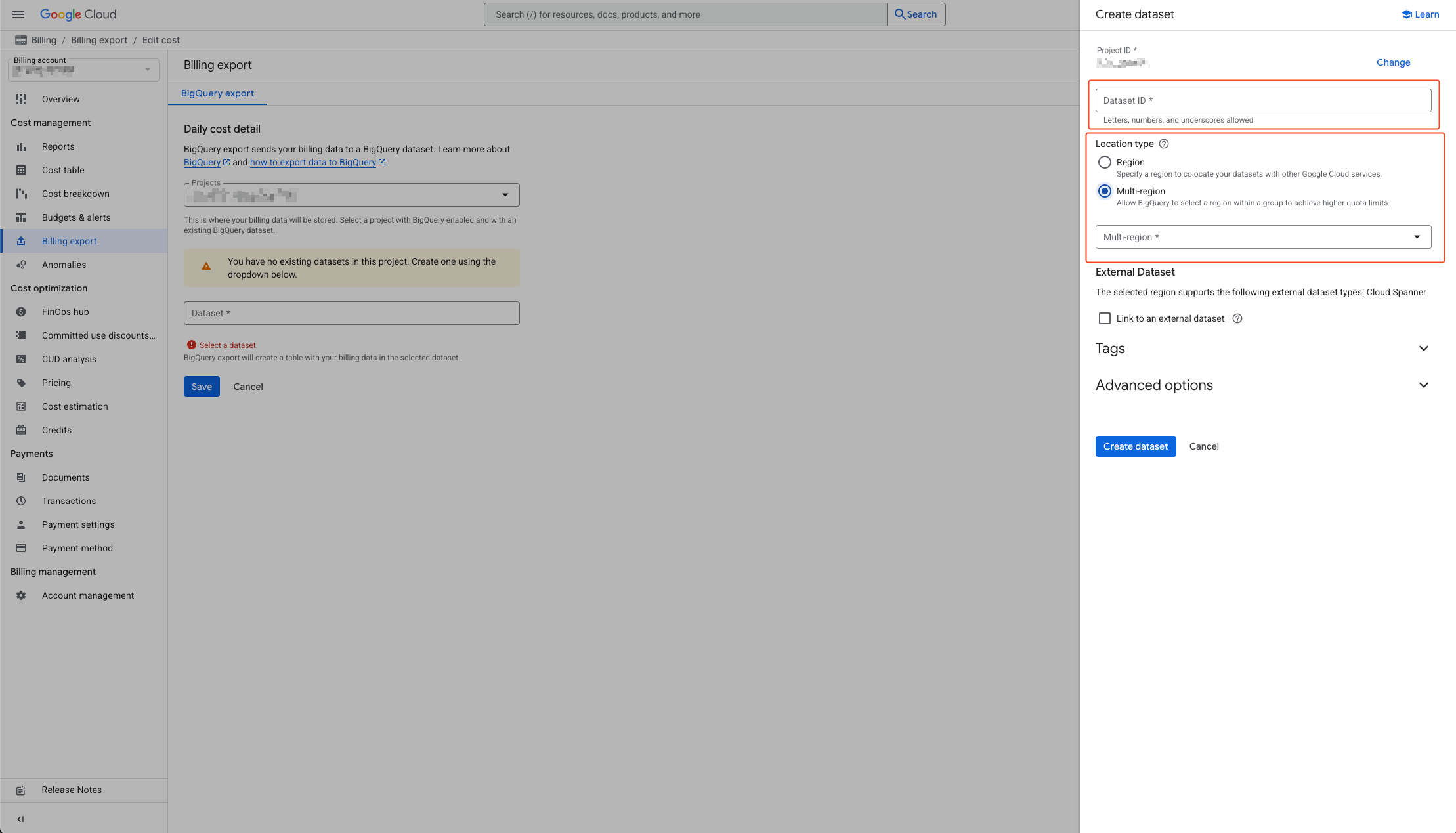
- Enter the dataset name in the activated sidebar on the right.
- Specify location type and select location. Please check the guide below before selecting.
Dataset Location Setup Guide
1. Why is region selection the most important?
- Cannot be changed: Dataset region cannot be changed after creation. If selected incorrectly, you must delete the dataset and recreate it.
- Direct cost impact: Incorrect region selection can result in ongoing unnecessary network costs.
- Performance degradation: When regions are different, data analysis (query) speed slows down each time.
2. Which region should I select? (Action Plan)
- 1st priority principle: Set it to the same region as your main GCP services such as servers (Compute Engine), storage (Cloud Storage), etc.
- How to check: First check which region your project’s other services are in, then decide the dataset region.
3. Example of incorrect region selection (cost occurrence scenario)
- Situation - My servers and storage are all in Seoul region, but I accidentally created BigQuery dataset in US region
- Problem - When querying data in Seoul, I need to communicate with BigQuery in US each time. During this process, additional inter-region data transfer (network egress) fees occur, and response speed also slows down.
4. “Single Region” vs “Multi-Region”
- Single Region: Like asia-northeast3 (Seoul), it means one specific city. It’s most advantageous for performance and cost prediction, so select single region unless there’s a special case.
- Multi-Region: Like ASIA, it’s a broad area including multiple countries. Data can be stored in one of several data centers in Asia. Unless for compliance or special purposes, it’s rarely used for billing data analysis purposes.
5. Scenario Examples
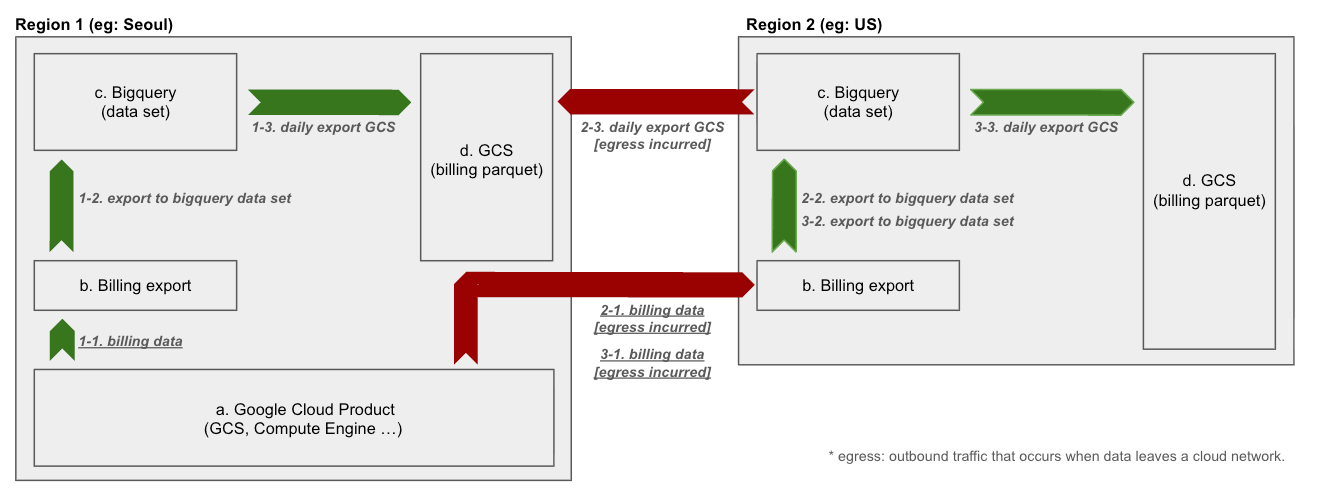
- Dataset Location: The GCP region where BigQuery table data is physically stored and managed. (e.g., asia-northeast3)
- Source Data Location: The location where the original data to be collected in BigQuery is stored. (e.g., Cloud Storage bucket region, Compute Engine region)
- Egress: Data transfer costs that occur due to network communication with other regions
Scenario 1: Optimal Configuration - All Component Locations Match
- Dataset Location: asia-northeast3 (Seoul)
- Source Data Location: asia-northeast3 (Seoul)
Analysis: Cost
When loading data from source data to BigQuery dataset, data transfer within the same region is not charged, so no network costs occur. This is the most cost-effective architecture.
Performance
Network latency during data ingestion and query processing is minimized. This ensures the highest processing speed and performance.
Conclusion
This is the standard architecture for data analysis systems and is the most recommended configuration in terms of cost and performance.
Scenario 2: Inefficient Configuration - Mismatch Between Dataset and Source Data Locations
- Dataset Location: asia-northeast3 (Seoul)
- Source Data Location: us-central1 (US Central)
Analysis: Cost
When source data from US region is transferred to BigQuery in Seoul region, inter-region network egress costs occur. As the amount of data increases, this cost can become a significant burden.
Performance
Data transfer between physically distant regions greatly increases loading operation latency, causing performance degradation of the entire data pipeline.
Conclusion
This configuration causes ongoing costs and performance degradation at the data collection stage, so it must be avoided.
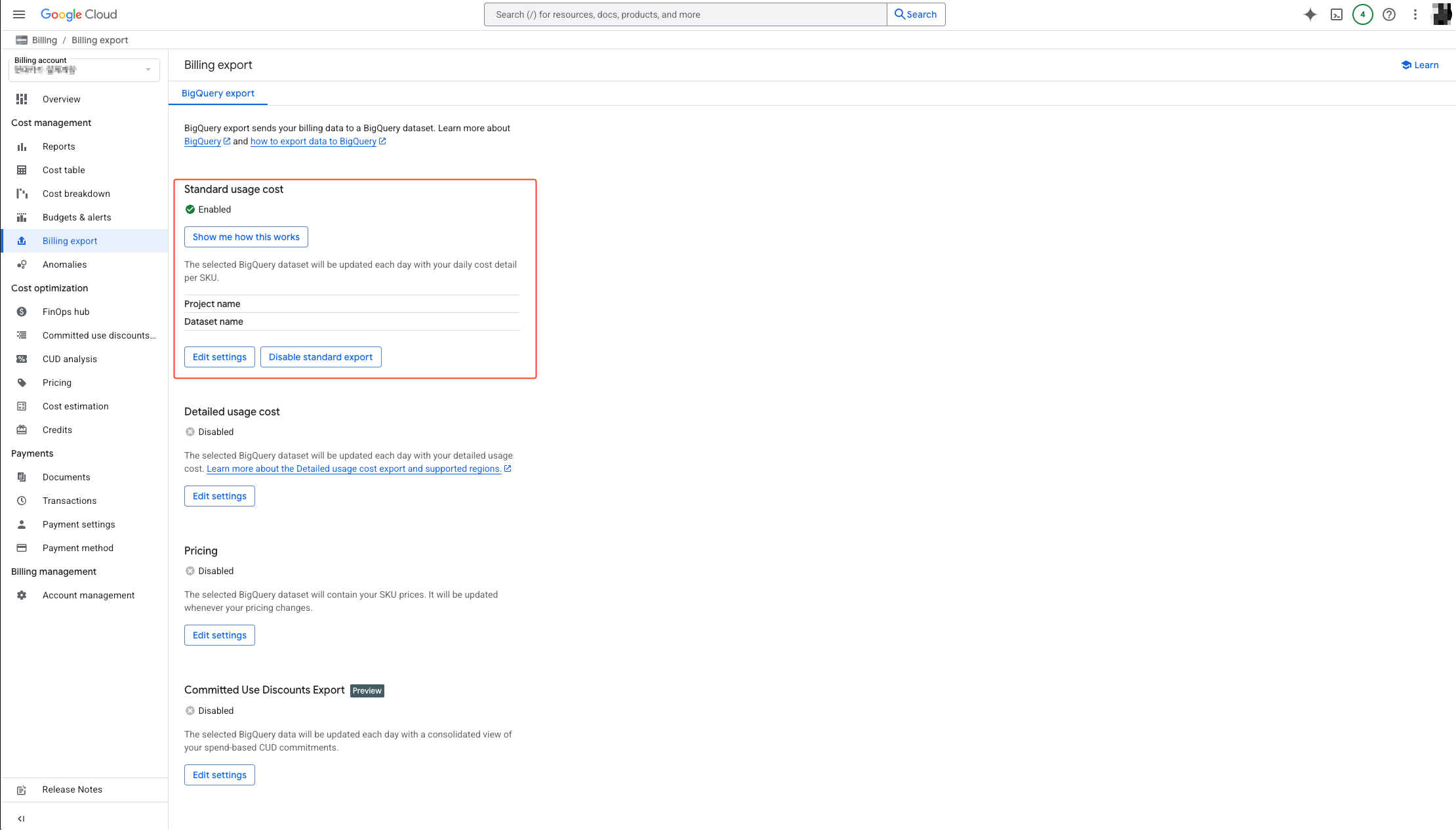
After understanding the above guide, verify that the project and dataset location have been successfully configured.
After all content is successfully completed, proceed to the next BigQuery setup.