Google Cloud BigQuery Setup
This guide provides instructions for setting up BigQuery to export data from the previously configured dataset to GCS at regular intervals.
Service Account Creation and Role Assignment
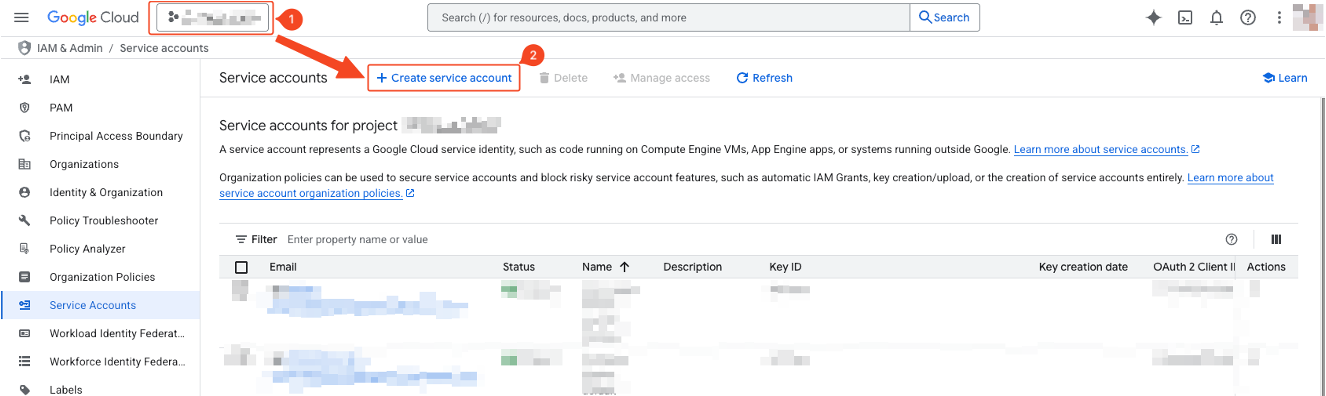
- Verify that the project for using GCS and BigQuery is correct.
- Click create service account.
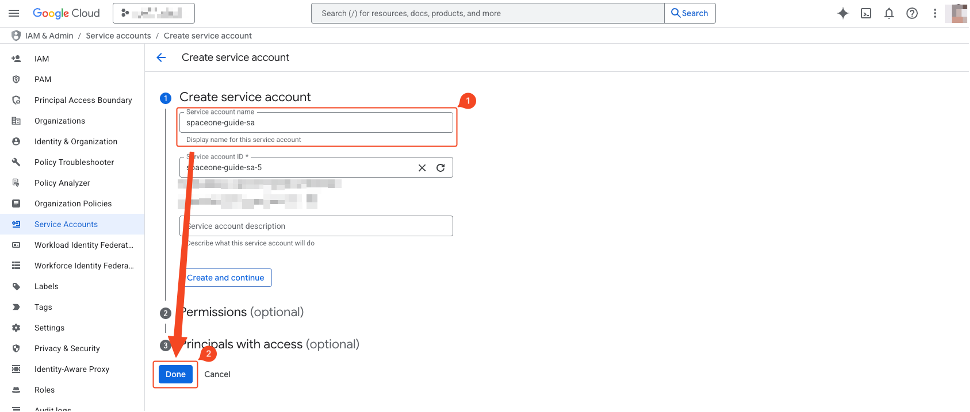
- Enter the service account name (e.g., billing_bigquery_export_account). It’s recommended to use an easily identifiable name.
- Click complete.
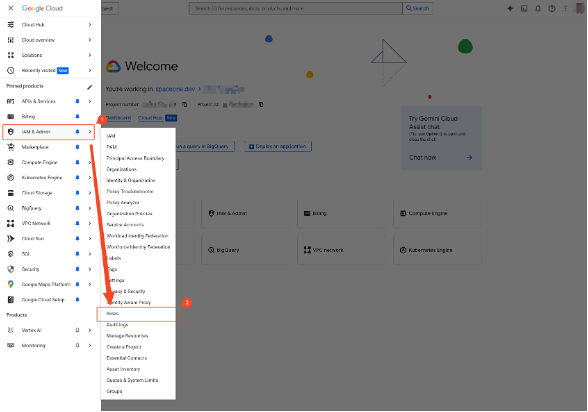 Select ‘IAM & Admin’ > ‘Roles’ from the navigation menu (☰) in the top left.
Select ‘IAM & Admin’ > ‘Roles’ from the navigation menu (☰) in the top left.
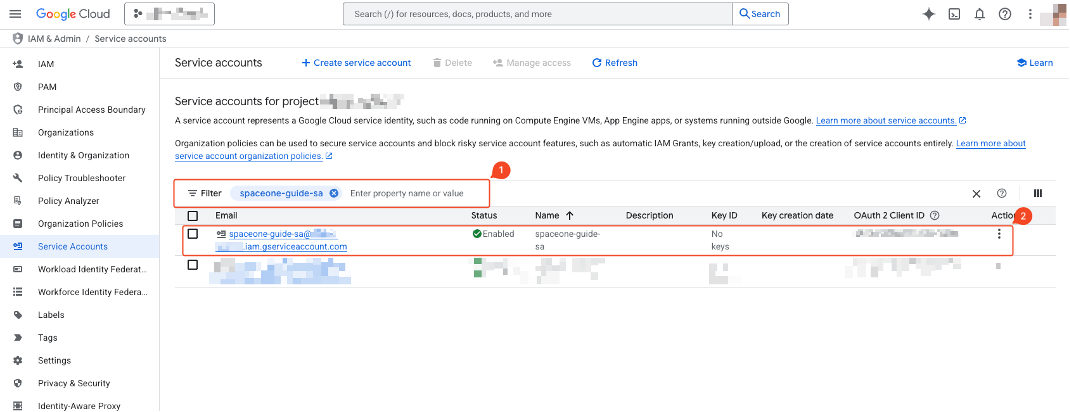
- Enter the name of the created service account (billing_bigquery_export_account) in the filter field.
- Click the searched service account.
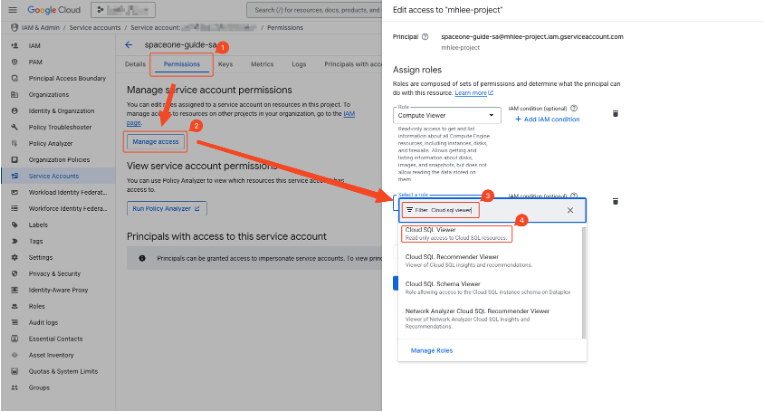
- Move to the Permissions tab.
- Click the permission control button to activate the right sidebar.
- Add the following 3 roles (BigQuery Data Viewer, BigQuery Job User, Storage Object Admin).
BigQuery Data Viewer
- bigquery.tables.get
- bigquery.tables.getData
BigQuery Job User
- bigquery.jobs.create
Storage Object Admin
- storage.objects.create
- storage.objects.list
- storage.objects.deleteGCS Bucket Creation
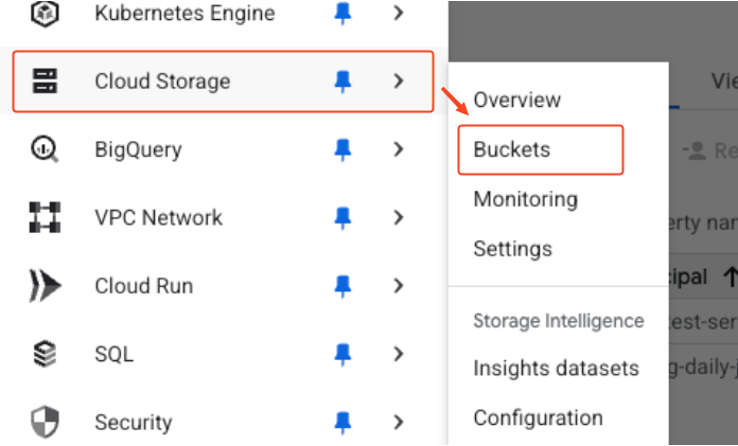 Select ‘Cloud Storage’ > ‘Buckets’ from the navigation menu (☰) in the top left.
Select ‘Cloud Storage’ > ‘Buckets’ from the navigation menu (☰) in the top left.
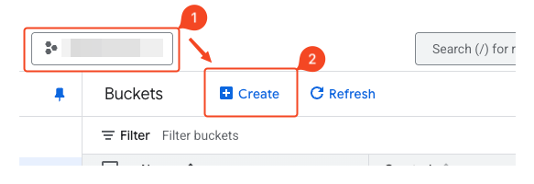
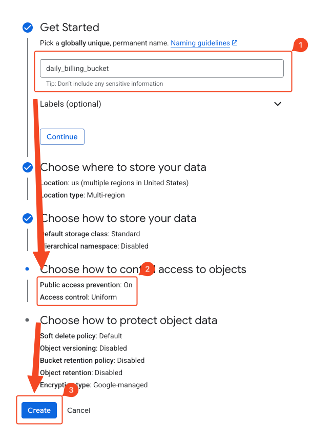
- Confirm project selection at the top and click create.
- Enter the bucket name.
- Verify that global access prevention is enabled.
- Click create to finish.
Scheduled Query Creation

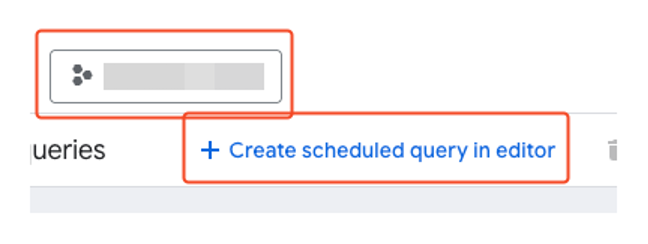
- Select ‘BigQuery’ > ‘Scheduled Queries’ from the navigation menu (☰) in the top left.
- Confirm the project at the top and click create scheduled query.
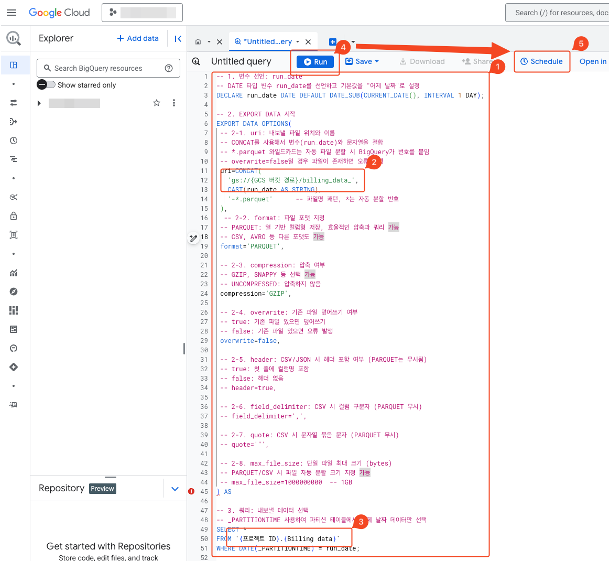
- Create three schedules by appropriately modifying the General Usage Costs , Adjustment Amount , and Linked Account queries according to the guidelines. Although there are three schedules, monthly files will be overwritten with the same pattern.
- Execute to verify that the query runs normally.
- Select “Schedule” from the top tools.
The queries create the following file tree structure:
- linked-accounts-YYYYMM-*.parquet
- billing-data-YYYYMM-*.parquet
General Usage Costs and Adjustment Amounts
General usage costs and adjustment amounts differ in terms of collection cycle, data characteristics, update timing, and final cost calculation method.
General usage costsare standard usage-based cost data aggregated daily, representing provisional amounts that are not yet finalized. These costs are aggregated almost in real-time as GCP service usage occurs and are added to the dataset daily. At this stage, the costs are not yet discounted or finalized.Adjustment amountsare all variable items reflected to finalize the billing amount after the month closes, including credits, promotions, taxes, and all other items that are ultimately reflected at month-end. Generally, data for the month is finalized in the early days of the following month, and these adjustments can appear as positive (+) or negative (-) amounts.
Scheduled Query SQL 1. General Usage Costs
SQL CODE
This is a query to perform export for general usage costs.
Enter the following items appropriately:
- GCS_BUCKET
- PROJECT_ID
- DATA_SET_ID
-- run_date variable declaration: DATE type with default value set to yesterday's date.
-- This date serves as the end date for data query period and the basis for file path generation.
DECLARE run_date DATE DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY);
-- start_of_month variable declaration: DATE type with default value set to the first day of the month containing 'run_date' (yesterday).
-- Example: If today is September 4, 2025, run_date is September 3, and start_of_month is September 1.
DECLARE start_of_month DATE DEFAULT DATE_TRUNC(run_date, MONTH);
-- EXPORT DATA statement: Exports query results to Google Cloud Storage (GCS).
EXPORT DATA OPTIONS(
-- uri: Specifies the GCS path and filename where data will be stored.
-- The path is dynamically generated based on the year and month of 'run_date' (yesterday).
uri=CONCAT(
'gs://{GCS_BUCKET}/{PROJECT_ID}/',
FORMAT_DATE('%Y/%m', run_date), -- 'YYYY/MM' format folder path (based on yesterday)
'/billing-data-',
FORMAT_DATE('%Y%m', run_date), -- 'YYYYMM' format filename part (based on yesterday)
'-*.parquet'
),
format='PARQUET', -- File format is Parquet
compression='GZIP', -- Compression method is GZIP
overwrite=true -- Allow overwriting existing files
) AS
-- Exports the results of the SELECT query below.
SELECT *
FROM `{DATA_SET_ID}`
WHERE
-- Only scans data partitions from '1st of this month' to 'yesterday' based on _PARTITIONTIME.
-- This improves query performance and reduces costs.
DATE(_PARTITIONTIME) BETWEEN start_of_month AND run_date
-- Filters data where invoice.month field matches the month containing 'yesterday' ('YYYYMM' format).
-- Example: If run_date is 2025-09-03, only data with invoice.month = '202509' is selected.
AND invoice.month = FORMAT_DATE('%Y%m', run_date);Scheduled Query SQL 2. Adjustment Amount
SQL CODE
This is a query to perform export for adjustment amount usage costs.
Enter the following items appropriately:
- GCS_BUCKET
- PROJECT_ID
- DATA_SET_ID
-- run_date variable declaration: DATE type with default value set to yesterday's date.
-- CURRENT_DATE() returns today's date, and subtracting INTERVAL 1 DAY calculates yesterday.
DECLARE run_date DATE DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY);
-- prev_month_start variable declaration: DATE type with default value set to the first day of the previous month.
-- Example: If today is September 4, 2025, then (1) subtract one month from CURRENT_DATE() (August 4, 2025),
-- (2) use DATE_TRUNC function to convert to the first day of that month (August 1, 2025).
DECLARE prev_month_start DATE DEFAULT DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTH), MONTH);
-- EXPORT DATA statement: Exports query results to Google Cloud Storage (GCS).
EXPORT DATA OPTIONS(
-- uri: Specifies the GCS path and filename where data will be stored.
-- Uses CONCAT function to dynamically generate the path.
uri=CONCAT(
'gs://{GCS_BUCKET}/{PROJECT_ID}/',
FORMAT_DATE('%Y/%m', prev_month_start), -- Generate 'YYYY/MM' format folder path
'/billing-data-',
FORMAT_DATE('%Y%m', prev_month_start), -- Generate 'YYYYMM' format filename part
'-*.parquet' -- Wildcard (*) indicating BigQuery can export to multiple files
),
format='PARQUET', -- File format is specified as Parquet
compression='GZIP', -- Compression method is specified as GZIP
overwrite=true -- Overwrite setting when files with the same name already exist
) AS
-- Exports the results of the SELECT query below.
SELECT * -- Selects all columns.
FROM `{DATA_SET_ID}` -- Target GCP billing data table
WHERE
-- _PARTITIONTIME refers to the partition date of the partitioned table.
-- Using this condition reduces the amount of data scanned, improving query performance and reducing costs.
-- Here, it limits scanning to only data partitions from '1st of last month' to 'yesterday'.
DATE(_PARTITIONTIME) BETWEEN prev_month_start AND run_date
-- Filters data where invoice.month field matches 'last month'.
-- Used together with _PARTITIONTIME filtering to extract exactly the billing data for the previous month.
AND invoice.month = FORMAT_DATE('%Y%m', prev_month_start);Scheduled Query SQL 3. Linked Account
SQL CODE
This is a query to perform export for Project information that exists in billing data for Linked Account.
Enter the following items appropriately:
- GCS_BUCKET
- PROJECT_ID
- DATA_SET_ID
-- run_date variable declaration: DATE type with default value set to yesterday's date.
-- This date serves as the end date for data query period and the basis for file path generation.
DECLARE run_date DATE DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY);
-- start_of_month variable declaration: DATE type with default value set to the first day of the month containing 'run_date' (yesterday).
-- Example: If today is October 30, 2025, run_date is October 29, and start_of_month is October 1.
DECLARE start_of_month DATE DEFAULT DATE_TRUNC(run_date, MONTH);
-- EXPORT DATA statement: Exports query results to Google Cloud Storage (GCS).
EXPORT DATA OPTIONS(
-- uri: Specifies the GCS path and filename where data will be stored.
-- The path is dynamically generated based on the year and month of 'run_date' (yesterday).
uri=CONCAT(
'gs://{GCS_BUCKET}/{PROJECT_ID}/linked_accounts/',
FORMAT_DATE('%Y/%m', run_date), -- 'YYYY/MM' format folder path (based on yesterday)
'/linked-accounts-',
FORMAT_DATE('%Y%m', run_date), -- 'YYYYMM' format filename part (based on yesterday)
'-*.parquet'
),
format='PARQUET', -- File format is Parquet
compression='GZIP', -- Compression method is GZIP
overwrite=true -- Allow overwriting existing files
) AS
-- Exports the results of the SELECT query below.
SELECT DISTINCT
project.id,
project.name
FROM `{DATA_SET_ID}`
WHERE
-- Only scans data partitions from '1st of this month' to 'yesterday' based on _PARTITIONTIME.
-- This improves query performance and reduces costs.
DATE(_PARTITIONTIME) BETWEEN start_of_month AND run_date
-- Filters data where invoice.month field matches the month containing 'yesterday' ('YYYYMM' format).
-- Example: If run_date is 2025-10-29, only data with invoice.month = '202510' is selected.
AND invoice.month = FORMAT_DATE('%Y%m', run_date)
ORDER BY
project.name,
project.id;DATA_SET_ID
DATA_SET_ID can be obtained after the dataset is successfully created in the previous Google Cloud Billing export setup
step.
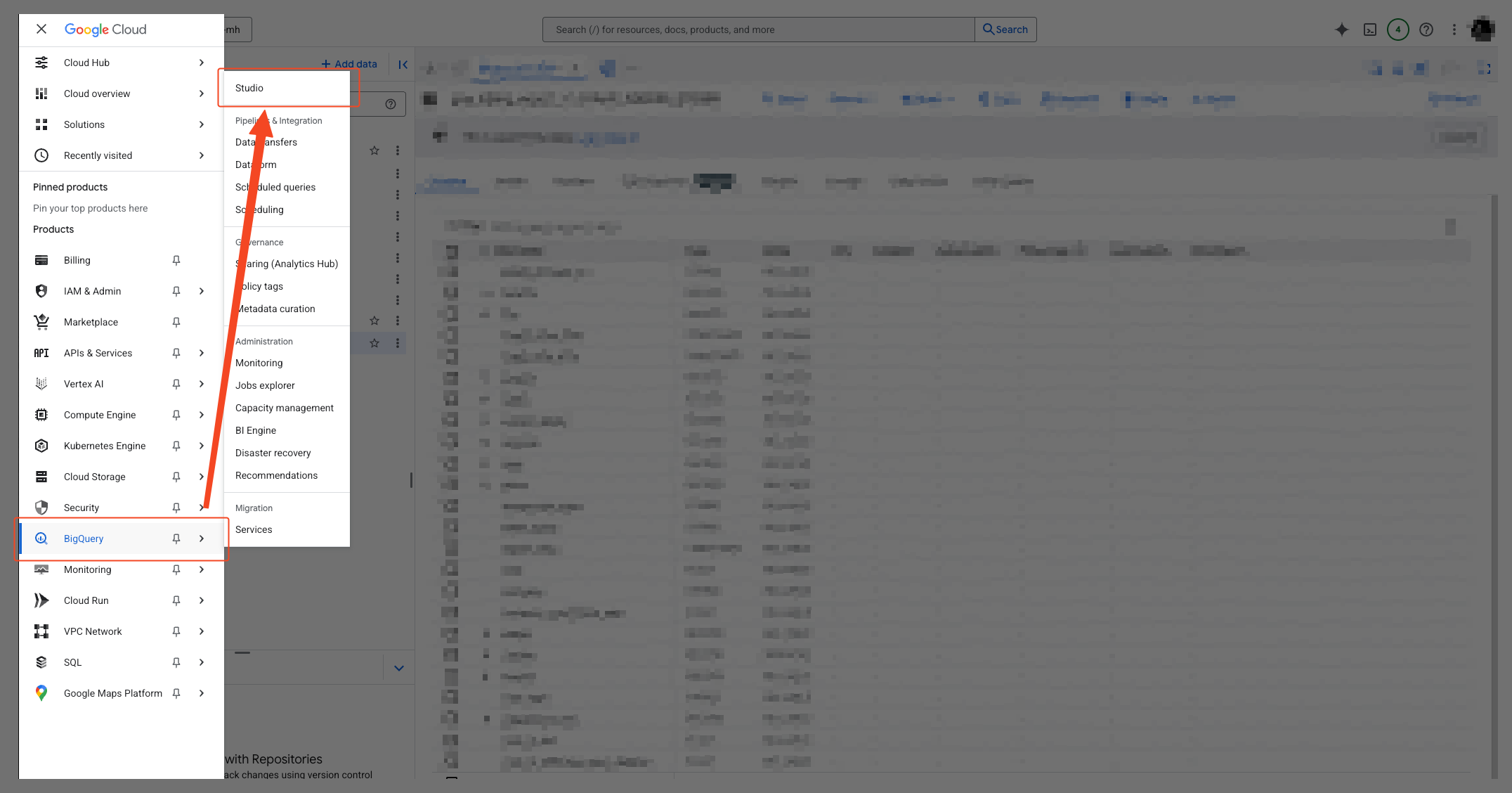
- Select ‘BigQuery’ > ‘Studio’ from the navigation menu (☰) in the top left.
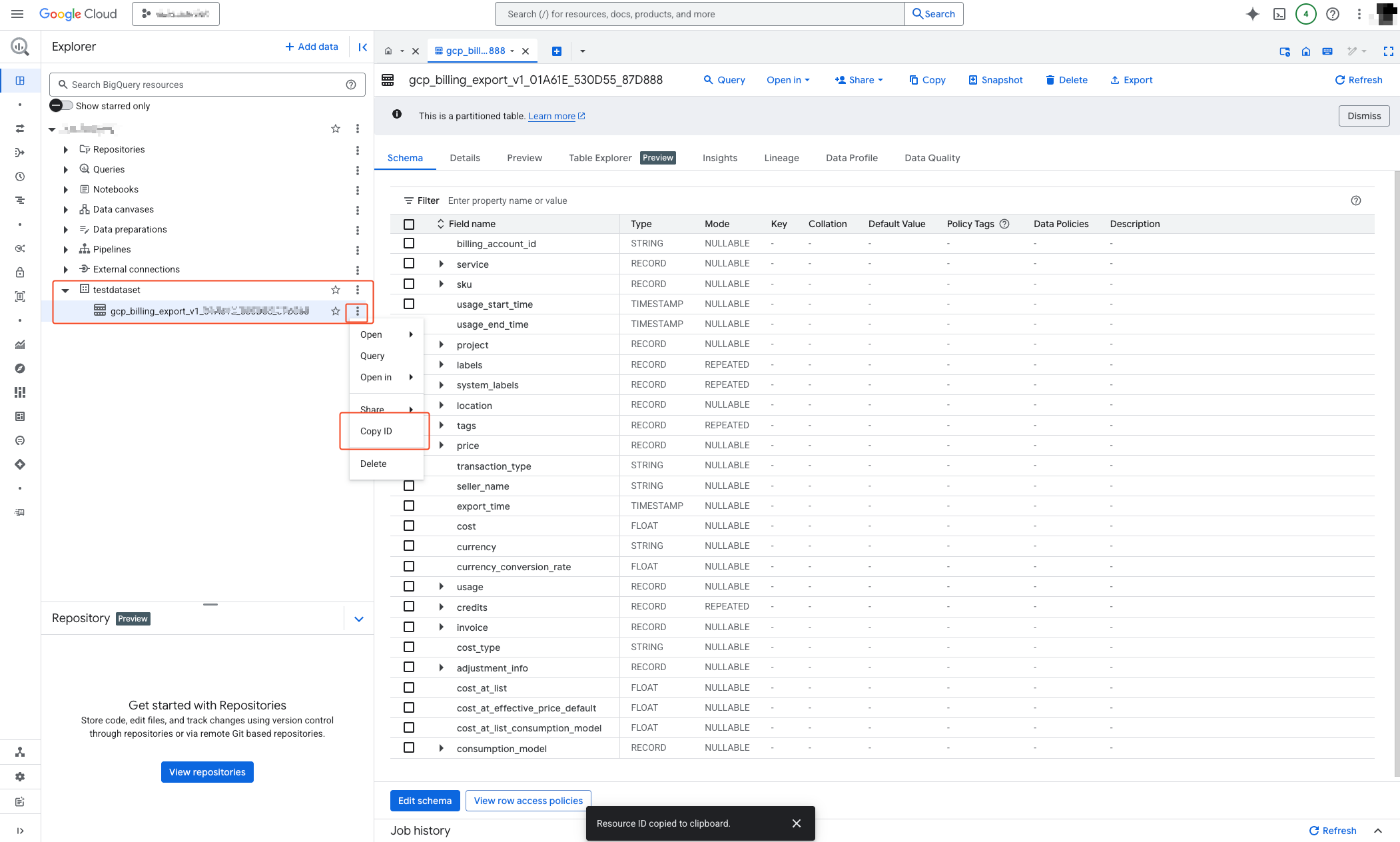
- Expand the created dataset and copy the ID from the options of the existing set.
- You can obtain an ID in the following format:
{PROJECT_ID}.{DATA_SET_NAME}.gcp_billing_export_v1_XXXXXX_XXXXXX_XXXXXXGCS_BUCKET
GCS_BUCKET can be obtained after the bucket is successfully created in the previous GCS Bucket Creation step.
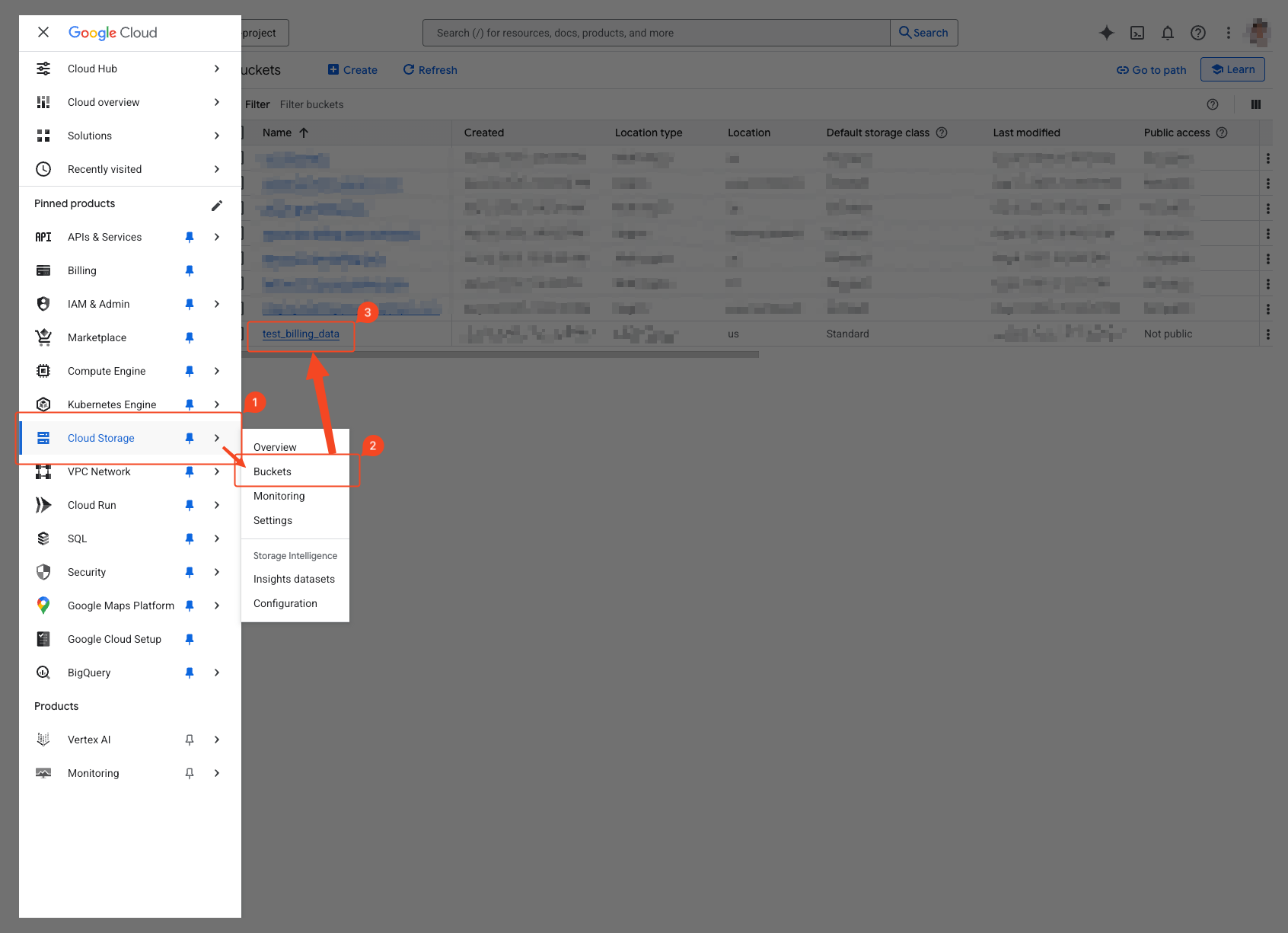
- Select Cloud Storage > ‘Bucket’ from the navigation menu (☰) in the top left.
- Select the bucket that was successfully created in the GCS Bucket Creation step.
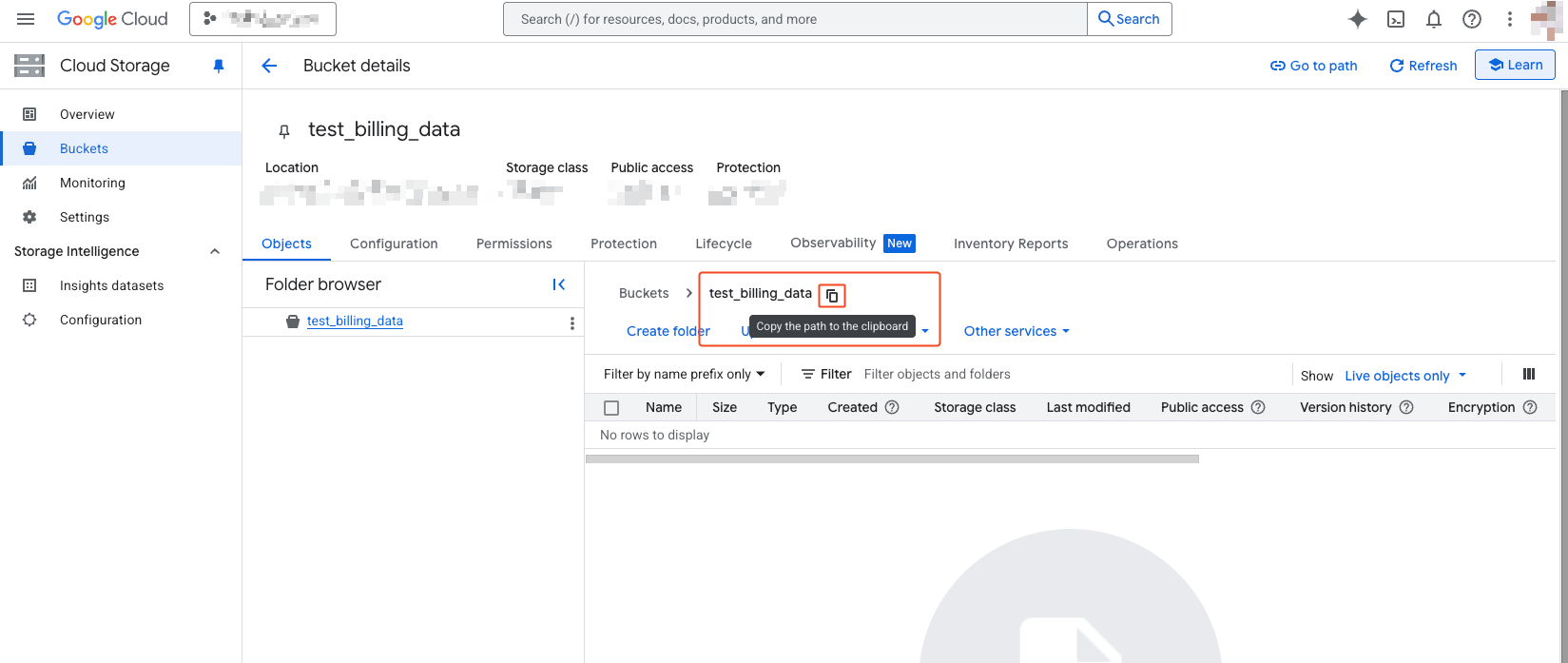
- Click the copy icon next to the path to copy the path.
- You can copy the following bucket name:
test_billing_dataScheduled Query Schedule Setup
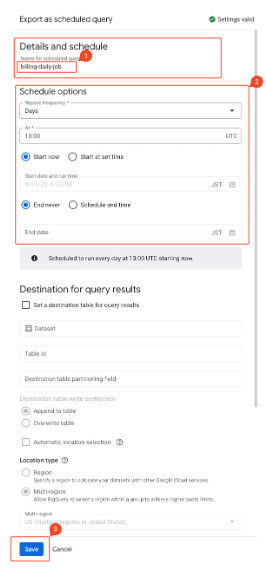
- Enter the name of the executed scheduler.
- Enter schedule options.
- Specify schedule options:
- Scheduled Query 1: General usage cost export
Daily at UTC 21:00(refer to plugin settings for execution time)- days / 21:00 / Start now / End never
- Scheduled Query 2: Adjustment amount usage cost export
Monthly on 1st-10th at UTC 23:00(refer to plugin settings for execution time)- Months / 1,2,3,4,5,6,7,8,9,10 / 23:00 / Start now / End never
- Scheduled Query 3: Linked Accounts information export
Daily at UTC 20:00(refer to plugin settings for execution time)- days / 20:00 / Start now / End never
- Scheduled Query 1: General usage cost export
Considerations for Scheduler Execution Cycle Settings
- Prevent Job Overlap: Ensure sufficient interval between scheduler executions so that the next job does not start before the data export job (Export Job) is completed.
- Expected Duration: Typical export jobs complete within 2-3 minutes, but the duration may increase depending on data volume and BigQuery query complexity.
- Recommended Settings: This guide configures scheduling at 1-2 hour intervals for stable operation.
- Set the execution entity to the service account created in Service Account Creation and Role Assignment .
- Click the save button to finish.
Execution Verification
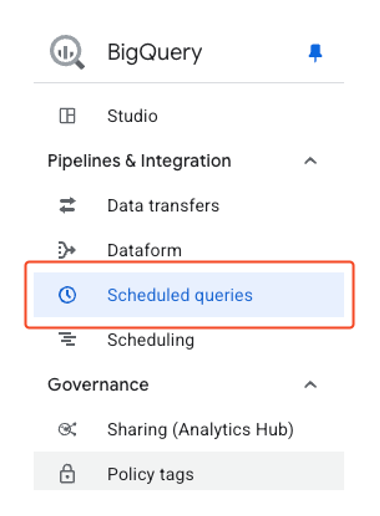
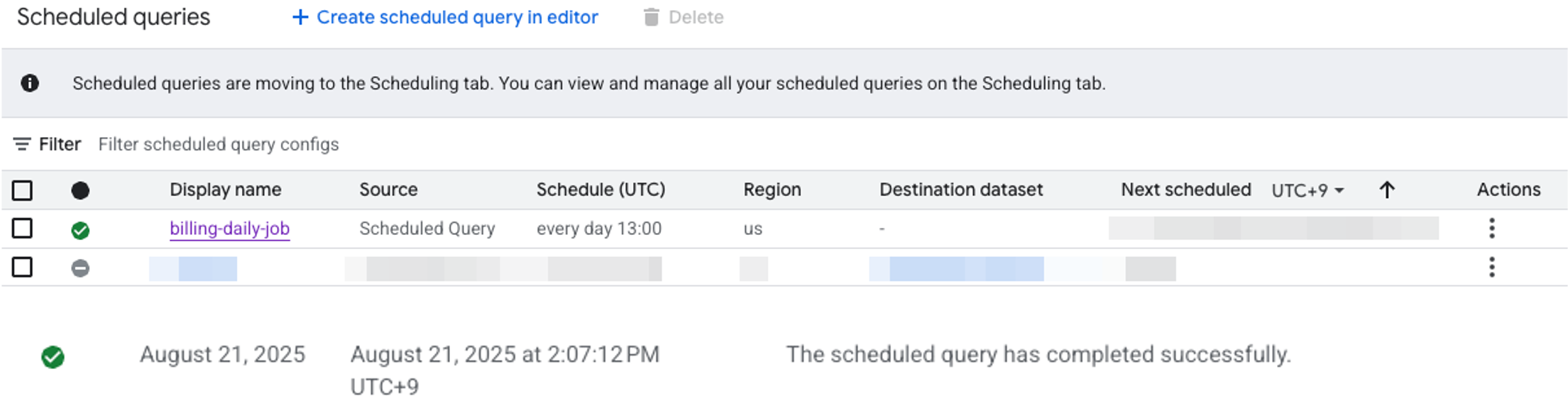
- Move to scheduled queries from the left sidebar menu.
- Verify the normal operation of the created scheduler on the screen.
- The created scheduler will run automatically once initially.
- If not working properly, you can click the scheduler to check error details or make modifications.
Execution Progress Verification
General usage costs are executed daily to collect cumulative monthly data, while adjustment amounts collect the previous month’s data in the early days of the following month after month-end. Data is systematically organized by year/month/day for easy analysis, with general usage costs updating almost in real-time and adjustment amounts updating monthly.
Collection Period: August 11, 2025 to October 15, 2025 (approximately 3 months)
- linked-accounts-202508-000000.parquet
- linked-accounts-202509-000000.parquet
- linked-accounts-202510-000000.parquet
- billing-data-202508-000000.parquet
- billing-data-202508-000001.parquet
- billing-data-202508-NNNNNN.parquet
- billing-data-202509-000000.parquet
- billing-data-202509-000001.parquet
- billing-data-202509-NNNNNN.parquet
- billing-data-202510-000000.parquet
- billing-data-202510-NNNNNN.parquet
Scheduled Query 1 (General Usage Costs):
- Execution Cycle: Runs daily at UTC 23:00
- Data Range: Usage data from the 1st of the month to the day before execution
- Collection Results:
- August: Executed August 11-31, collected August 1-30 data
- September: Executed September 1-30, collected September 1-30 data
- October: Executed October 1-15, collected October 1-14 data
Scheduled Query 2 (Adjustment Amount):
- Execution Cycle: Runs on the 1st-10th of each month at UTC 23:00
- Data Range: Previous month’s adjustment data (credits, discounts, taxes, etc.)
- Collection Results:
- August adjustment data: Executed September 1-10, collection completed
- September adjustment data: Executed October 1-10, collection completed
- October adjustment data: Scheduled to execute November 1-10 (not yet collected)
Scheduled Query 3 (Linked Accounts):
- Execution Cycle: Runs daily at UTC 23:00
- Data Range: Project information from usage data from the 1st of the month to the day before execution
- Collection Results:
- August: Executed August 11-31, collected August 1-30 data
- September: Executed September 1-30, collected September 1-30 data
- October: Executed October 1-15, collected October 1-14 data